TL;DR: This is a story about how we trimmed 70% of our JSON parsing cloud costs by writing an open-source Go library called marshmallow. 🍬🚀
Motivation
When we think about JSON parsing, the first use case that pops to mind usually involves a predetermined structure. It’s the simplest way for two components to interact: they both agree on a message schema and then use JSON to carry it around - super easy. 😊
This is a popular and intuitive choice, although it’s not the most efficient. ⚠️
When the structure of the message is fully expected, libraries that leverage code generation perform best. However, using other protocols to communicate improves performance by a lot more. For instance, strict, binary protocols like protobuf and avro would improve networking efficiency due to reduced message size and then trim down CPU usage due to a much more efficient encoding and decoding mechanism. 👏🏾
This is to be expected. Strict schema environments are not where JSON protocol really shines. JSON, however, possesses something that the others don’t: it fully specifies the name and the type of each field in the data. In other words, it carries both the data and the structure itself. 🤔💡 This makes it the go-to choice for document databases and other non-schema-strict use cases. In our case, it was unstructured structs: when some of the fields are known and some aren’t. We’ll provide an example shortly.
Performance-Driven
Marshmallow’s journey began with an important StackOverflow question. It simply asks what’s the best way to parse a JSON object when some of the fields are known and some aren’t. We were facing the same problem and actively looked for a solution, so we started digging into it, investigating and exploring the solutions proposed and any other solution we could find. 👩💻🕵🏾♀️
Use a Map
The first thing we can do is use a native map[string]any. This captures all the data and allows you to access it. However, it’s inefficient, inconvenient and unsafe. Consider the following use case: in order to determine whether a user is allowed to drive, you need to reference two specific fields from the data (ageand has_drivers_license), then, iterate the rest of the fields and look for prior convictions.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
// use a native go map
func isAllowedToDrive(data []byte) (bool, error) {
result := make(map[string]any)
err := json.Unmarshal(data, &result)
if err != nil {
return false, err
}
age, ok := result["age"]
if !ok {
return false, nil
}
a, ok := age.(float64)
if !ok {
return false, nil
}
if a < 17 {
return false, nil
}
hasDriversLicense, ok := result["has_drivers_license"]
if !ok {
return false, nil
}
h, ok := hasDriversLicense.(bool)
if !ok {
return false, nil
}
if !h {
return false, nil
}
for key := range result {
if strings.Contains(key, "prior_conviction") {
return false, nil
}
}
return true, nil
}
Obviously, this is a lot of code to write for such a simple task. But more importantly, this is error-prone. Typos and bad casting cannot be enforced by the compiler, which makes refactoring a nightmare. Changing a field name or type requires manual searching and fixing of all relevant places, otherwise, your code breaks in runtime. 😵
Additionally, it has performance implications - map lookups and casting are slower than simple field referencing.
Lastly, everything turns into chaos when the structure contains non-primitives. Handling just this data: {"foo":[{"counter":15},{"counter":"16"}]} requires the following code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
func handle(input []byte) error {
data := make(map[string]any)
err := json.Unmarshal(input, &data)
if err != nil {
return err
}
rawFoo, exists := data["foo"]
if !exists {
return errors.New("missing foo")
}
foo, ok := rawFoo.([]any)
if !ok {
return errors.New("invalid foo")
}
for _, rawElement := range foo {
element, ok := rawElement.(map[string]any)
if !ok {
return errors.New("invalid element")
}
rawCounter, exists := element["counter"]
if !exists {
return errors.New("missing counter")
}
floatCounter, ok := rawCounter.(float64)
if !ok {
return errors.New("invalid counter")
}
counter := int(floatCounter)
fmt.Printf("counter is %d", counter)
}
return nil
}
Ugh! 🥴🔫
Unmarshal Twice
Unmarshalling twice solves all of those problems - you unmarshal once into a struct, then unmarshal once again into a map. This way, you get efficient, safe, and convenient access to known fields via struct, and dynamic access to all the data like before. The first example once again:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// unmarshal twice
type driver struct {
Age int `json:"age"`
HasDriversLicense bool `json:"has_drivers_license"`
}
func isAllowedToDrive(data []byte) (bool, error) {
d := driver{}
err := json.Unmarshal(data, &d)
if err != nil {
return false, err
}
result := make(map[string]any)
err = json.Unmarshal(data, &result)
if err != nil {
return false, err
}
if d.Age < 17 || !d.HasDriversLicense {
return false, nil
}
for key := range result {
if strings.Contains(key, "prior_conviction") {
return false, nil
}
}
return true, nil
}
And the second one:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// unmarshal twice non primitives
type data struct {
Foo []struct {
Counter int `json:"counter"`
} `json:"foo"`
}
func handle(input []byte) error {
d := data{}
err := json.Unmarshal(input, &d)
if err != nil {
return err
}
for _, element := range d.Foo {
fmt.Printf("counter is %d", element.Counter)
}
return nil
}
Ah, that’s more like it! 🤗😊
…But wait, JSON parsing is a very expensive operation. The portion of compute cost and time that was devoted to JSON parsing has now doubled. In our case that was a LOT. 💸💰💵🤑
Unmarshal Into a Raw Map
Let’s try to keep the benefits, but optimize performance. For that end, we’ll try passing over the JSON data just once:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
// unmarshal into a raw map
type driver struct {
Age int `json:"age"`
HasDriversLicense bool `json:"has_drivers_license"`
}
func isAllowedToDrive(data []byte) (bool, error) {
fields := make(map[string]json.RawMessage)
err := json.Unmarshal(data, &fields)
if err != nil {
return false, err
}
d := driver{}
result, err := unmarshal(fields, &d)
if d.Age < 17 || !d.HasDriversLicense {
return false, nil
}
for key := range result {
if strings.Contains(key, "prior_conviction") {
return false, nil
}
}
return true, nil
}
func unmarshal(fields map[string]json.RawMessage, v any) (map[string]any, error) {
refValue := reflect.ValueOf(v)
result := make(map[string]any)
for key, value := range fields {
var parsed any
fieldValue := refValue.FieldByName(key)
if !fieldValue.IsZero() {
parsed = fieldValue.Interface()
}
err := json.Unmarshal(value, &parsed)
if err != nil {
return nil, err
}
result[key] = parsed
}
return result, nil
}
This unmarshal function is now reusable. What json.RawMessage does is actually instruct the parser to skip this field, keeping it in its raw []byte shape. This allows us to first parse the structure into a raw map, and then parse the actual fields in it one by one, according to our struct’s schema. Note that this way we unmarshal each piece of the data only once.
High expectations, great disappointments. 😞 This approach doesn’t have any significant impact, it performs much like the unmarshal twice approach (see benchmark results below). Let’s move on then.
Unmarshal Into a Pointer Map
Using go/codec or similar libraries, you can initialize a new map and point its keys to the struct fields.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// using go codec
type driver struct {
Age int `json:"age"`
HasDriversLicense bool `json:"has_drivers_license"`
}
func isAllowedToDrive(data []byte) (bool, error) {
d := driver{}
result := make(map[string]any)
result["age"] = &d.Age
result["has_drivers_license"] = &d.HasDriversLicense
err := codec.NewDecoderBytes(data, &codec.JsonHandle{}).Decode(&result)
if err != nil {
return false, err
}
if d.Age < 17 || !d.HasDriversLicense {
return false, nil
}
for key := range result {
if strings.Contains(key, "prior_conviction") {
return false, nil
}
}
return true, nil
}
This method produces two nice outcomes. Not only will the unmarshalling of those keys be typed according to the struct schema, but it will also populate both the struct and the map in a single iteration. 💪😎
Still, there are two significant downsides. First, it performs better than the previous approaches, yet not as good as it could (see benchmark results below). Second, it requires additional coding to manually point the map keys to the struct fields. This is a problem not because we’re lazy, but because it introduces potential maintainability issues - adding new fields to the struct requires manual hooking, otherwise parsing behavior breaks. Once again - extra manual coding now means refactoring becomes harder later. 😵
You can sort out this issue by using the reflection API, however, this will hurt performance even more. 📈
Marshmallow’s Solution
Marshmallow optimizes all of that - both the need for explicit coding and the performance overhead.
Equipped with a dedicated JSON tokenizer, marshmallow uses the given struct as schema instructions and populates both the struct and a resulting map. It keeps the usage of reflection API to a bare minimum, to even further optimize performance.
![]()
The results are beautiful and proof of a worthy effort. Marshmallow outperformed unmarshalling into a raw map by ~x3 🥳🎉🏃🏾♀️📉 (see benchmark results below).
After stabilizing the API and fully testing the behavior, we decided to gradually integrate marshmallow into production. Despite the significant buildup, the results in production did not let us down. Aside from a much cleaner and more maintainable source code, we examined profiling results and our monitoring tools and discovered we trimmed 70% of our JSON parsing CPU usage. 🤯😮💖
This number is insane. How is marshmallow able to boost by x3 the performance of unmarshaling twice, although it must at least perform half the work? It does it by reducing reflect operations and caching their results when possible. The resulting code is lean enough to reach this type of performance.
Full benchmark results:
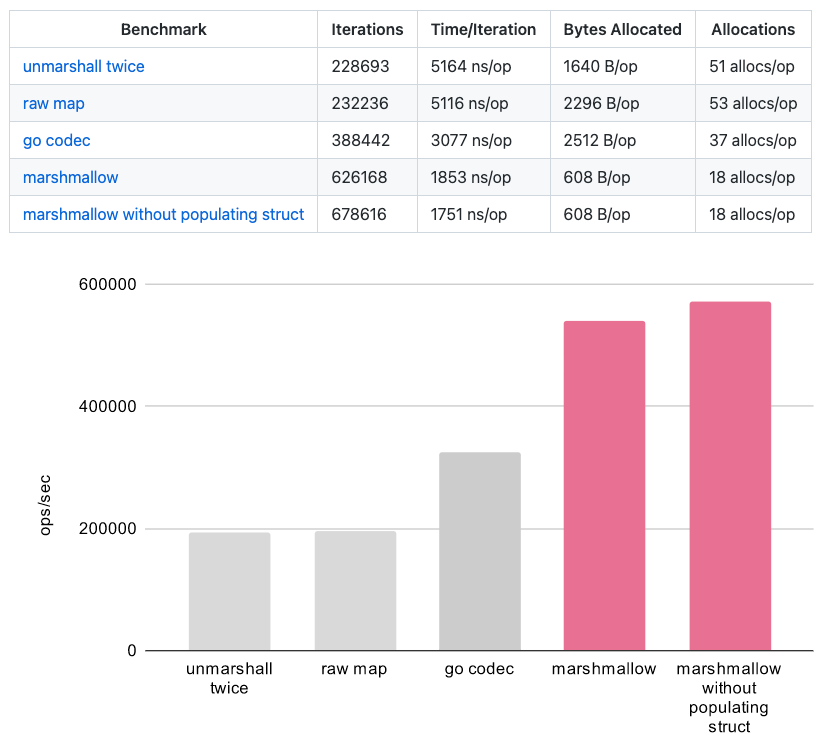
The full benchmark test can be found here.
And how does the code look? Clean and beautiful. 😊 But most of all - maintainable.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// using marshmallow
type driver struct {
Age int `json:"age"`
HasDriversLicense bool `json:"has_drivers_license"`
}
func isAllowedToDrive(data []byte) (bool, error) {
d := driver{}
result, err := marshmallow.Unmarshal(data, &d)
if err != nil {
return false, err
}
if d.Age < 17 || !d.HasDriversLicense {
return false, nil
}
for key := range result {
if strings.Contains(key, "prior_conviction") {
return false, nil
}
}
return true, nil
}
Schema Flexibility and Error Handling
Most JSON parsing libraries conduct strict schema validations. If they encounter an unexpected type, they stop and return an error. In some use cases, a more robust parsing is required. For instance - parse and return just the valid data, or report all schema errors instead of just the first one. Other use cases require a different approach - retain all the original data at any cost. Marshmallow provides all of those by setting an unmarshalling mode. 🎁
Marshmallow mode allows you to control how unmarshaling should behave when encountering unexpected values.
ModeFailOnFirstErroris the default mode. It makes unmarshalling terminate immediately on any kind of error.ModeAllowMultipleErrorsmakes unmarshalling keep decoding even if errors are encountered. In case of such an error, the erroneous value will be omitted from the result. Eventually, all errors will all be returned, alongside the partial result. This mode provides solutions for both use cases of parse and return just the valid data, and report all schema errors.ModeFailOverToOriginalValuemakes unmarshalling keep decoding even if errors are encountered too. In case of an error, the original external value will be placed in the result data even though it does not meet the schematic requirements. Eventually, all errors will be returned, alongside the full result. Note that theresultmap may contain values that do not match the struct schema. This mode provides a solution for the use case of retaining all the original data at any cost.
Quick Examples
Marshmallow provides an API to unmarshal either from a []byte, or from an already unmarshalled JSON map. The latter provides a cheap ability to fix and validate concrete typing in already existing JSON maps.
Full examples can be found on marshmallow’s GitHub.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
// some examples
type exampleStruct struct {
Foo string `json:"foo"`
Boo []int `json:"boo"`
}
func ExampleUnmarshal() {
// enable marshmallow cache to boost up performance by reusing field type information.
marshmallow.EnableCache()
// unmarshal with mode marshmallow.ModeFailOnFirstError and valid value
// this will finish unmarshalling and return a nil err
v := exampleStruct{}
result, err := marshmallow.Unmarshal([]byte(`{"foo":"bar","boo":[1,2,3]}`), &v)
fmt.Printf("ModeFailOnFirstError and valid value: v=%+v, result=%+v, err=%T\n", v, result, err)
// Output: ModeFailOnFirstError and valid value: v={Foo:bar Boo:[1 2 3]}, result=map[boo:[1 2 3] foo:bar], err=<nil>
// unmarshal with mode marshmallow.ModeFailOnFirstError and invalid value
// this will return nil result and an error
v = exampleStruct{}
result, err = marshmallow.Unmarshal([]byte(`{"foo":2,"boo":[1,2,3]}`), &v)
fmt.Printf("ModeFailOnFirstError and invalid value: result=%+v, err=%T\n", result, err)
// Output: ModeFailOnFirstError and invalid value: result=map[], err=*jlexer.LexerError
// unmarshal with mode marshmallow.ModeAllowMultipleErrors and valid value
// this will finish unmarshalling and return a nil err
v = exampleStruct{}
result, err = marshmallow.Unmarshal([]byte(`{"foo":"bar","boo":[1,2,3]}`), &v,
marshmallow.WithMode(marshmallow.ModeAllowMultipleErrors))
fmt.Printf("ModeAllowMultipleErrors and valid value: v=%+v, result=%+v, err=%T\n", v, result, err)
// Output: ModeAllowMultipleErrors and valid value: v={Foo:bar Boo:[1 2 3]}, result=map[boo:[1 2 3] foo:bar], err=<nil>
// unmarshal with mode marshmallow.ModeAllowMultipleErrors and invalid value
// this will return a partially populated result and an error
v = exampleStruct{}
result, err = marshmallow.Unmarshal([]byte(`{"foo":2,"boo":[1,2,3]}`), &v,
marshmallow.WithMode(marshmallow.ModeAllowMultipleErrors))
fmt.Printf("ModeAllowMultipleErrors and invalid value: result=%+v, err=%T\n", result, err)
// Output: ModeAllowMultipleErrors and invalid value: result=map[boo:[1 2 3]], err=*marshmallow.MultipleLexerError
// unmarshal with mode marshmallow.ModeFailOverToOriginalValue and valid value
// this will finish unmarshalling and return a nil err
v = exampleStruct{}
result, err = marshmallow.Unmarshal([]byte(`{"foo":"bar","boo":[1,2,3]}`), &v,
marshmallow.WithMode(marshmallow.ModeFailOverToOriginalValue))
fmt.Printf("ModeFailOverToOriginalValue and valid value: v=%+v, result=%+v, err=%T\n", v, result, err)
// Output: ModeFailOverToOriginalValue and valid value: v={Foo:bar Boo:[1 2 3]}, result=map[boo:[1 2 3] foo:bar], err=<nil>
// unmarshal with mode marshmallow.ModeFailOverToOriginalValue and invalid value
// this will return a fully unmarshalled result, failing to the original invalid values, and an error
v = exampleStruct{}
result, err = marshmallow.Unmarshal([]byte(`{"foo":2,"boo":[1,2,3]}`), &v,
marshmallow.WithMode(marshmallow.ModeFailOverToOriginalValue))
fmt.Printf("ModeFailOverToOriginalValue and invalid value: result=%+v, err=%T\n", result, err)
// Output: ModeFailOverToOriginalValue and invalid value: result=map[boo:[1 2 3] foo:2], err=*marshmallow.MultipleLexerError
}
Conclusion
We faced an engineering problem and identified its unique set of constraints, then we wrote code to directly tackle the problem with a proper solution, and the numbers were beautiful.
We were able to boost performance by ~x3 in benchmarking tests and trim down ~70% of our JSON CPU usage in production. 😁
Marshmallow does not perform any kind of magic to achieve these results, rather, those are an indication of the impact of choosing the right tool for the job. 🧰⚒️😎
![]()
Shout out to the amazing team at HUMAN for brainstorming, consulting, contributing, reviewing, and naming. You guys are awesome as always. 🙏😁