
The Go language was first announced in late 2009, and officially released in 2012, but has only started gaining serious traction in the last several years. It was one of the fastest growing languages of 2018, and is the third most wanted programing language of 2019.
Being relatively new, the Go community is not yet very strict about coding guidelines. If we take a look at coding conventions of communities that have been around for longer, Java for instance, we find most projects have a similar structure. This can be very helpful when writing big code bases, yet a lot of people would argue that for modern use-cases this can be counterproductive. As we advance towards writing micro systems and maintain smaller code bases, Go flexibility regarding project structure has a lot to offer.
We’ve all seen the Golang hello world http example in contrast to other languages like Java. There isn’t a dramatic difference between the two in terms of complexity nor in the amount of code. However, it shows the fundamental differences in the approach Go encourages us to take — when possible, write simple code. Ignoring the Object Oriented aspects of Java, I think the most important take from these code snippets is that Java requires creating a dedicated instance for each operation (HttpServer instance) while Go encourages you to use a global singleton.
This implies that you’ll have less code to maintain, fewer references to pass around. If you know you’re going to create only one server (which is usually the case) why work so hard? This philosophy becomes very powerful as your code base grows. Still, life can be tough 😩 This is because there are still several levels of abstraction to choose from, and mistakenly combining those may hold serious pitfalls.
…But don’t worry, at HUMAN, we’re here to help! 🦸
I’ll highlight three approaches to organizing and structuring your Go code. Each approach introduces a different level of abstraction. Then, I’ll compare them all and cover the use cases for each one.
Our goal is to implement an HTTP server containing user information (Main DB in the figure below), where each user has a role (e.g. basic, moderator, admin), with an additional database (Configuration DB in the figure below), containing sets of permissions available for each role (e.g. read, write, edit). Our HTTP server should implement an endpoint that returns a set of permissions for a given user ID.
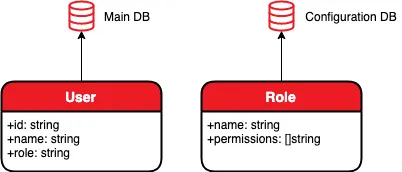
Let’s further assume that the configuration DB rarely changes and has long loading times, so we want to maintain it in-memory, load it once the server starts, and refresh it once per hour.
The entire code can be found in the article repository on GitHub.
Approach I: Single Package
The single package approach introduces a flat hierarchy, in which the entire server is implemented in one package. Full code.
Note: the comments in the code snippets are important for understanding the principles of each approach.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
package main
import (
"net/http"
)
// As noted above, since we plan to only have one instance
// for those 3 services, we'll declare a singleton instance,
// and make sure we only use them to access those services.
var (
userDBInstance userDB
configDBInstance configDB
rolePermissions map[string][]string
)
func main() {
// Our singleton instances will later be assumed
// initialized, it is the initiator's responsibility
// to initialize them.
// The main function will do it with concrete
// implementation, and test cases, if we plan to
// have those, may use mock implementations instead.
userDBInstance = &someUserDB{}
configDBInstance = &someConfigDB{}
initPermissions()
http.HandleFunc("/", UserPermissionsByID)
http.ListenAndServe(":8080", nil)
}
// This will keep our permissions up to date in memory.
func initPermissions() {
rolePermissions = configDBInstance.allPermissions()
go func() {
for {
time.Sleep(time.Hour)
rolePermissions = configDBInstance.allPermissions()
}
}()
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package main
// We use interfaces as the types of our database instances
// to make it possible to write tests and use mock implementations.
type userDB interface {
userRoleByID(id string) string
}
// Note the naming `someConfigDB`. In actual cases we use
// some DB implementation and name our structs accordingly.
// For example, if we use MongoDB, we name our concrete
// struct `mongoConfigDB`. If used in test cases,
// a `mockConfigDB` can be declared, too.
type someUserDB struct {}
func (db *someUserDB) userRoleByID(id string) string {
// Omitting the implementation details for clarity...
}
type configDB interface {
allPermissions() map[string][]string // maps from role to its permissions
}
type someConfigDB struct {}
func (db *someConfigDB) allPermissions() map[string][]string {
// implementation
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
package main
import (
"fmt"
"net/http"
"strings"
)
func UserPermissionsByID(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := userDBInstance.userRoleByID(id)
permissions := rolePermissions[role]
fmt.Fprint(w, strings.Join(permissions, ", "))
}
Note we still use separate files to divide different responsibilities. This makes it more readable and easier to maintain.
Approach II: Coupled Packages
In this approach we introduce packages. A package should have sole responsibility over some behavior. Here we allow packages to interact with each other, thus needing to maintain less code. Still, we have to make sure we’re not breaking the principle of responsibility to ensure each piece of logic is implemented completely in a single package. Another important guideline for this approach is that since Go disallows circular dependencies between packages, we have to create a neutral package containing only bare definitions of interfaces and singleton instances. This will ensure our code is free from circular dependencies. Full code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package main
// Note how the main package is the only one importing
// packages other than the definition package.
import (
"github.com/myproject/config"
"github.com/myproject/database"
"github.com/myproject/definition"
"github.com/myproject/handler"
"net/http"
)
func main() {
// This approach also uses singleton instances, and
// again it's the initiator's responsibility to make
// sure they're initialized.
definition.UserDBInstance = &database.SomeUserDB{}
definition.ConfigDBInstance = &database.SomeConfigDB{}
config.InitPermissions()
http.HandleFunc("/", handler.UserPermissionsByID)
http.ListenAndServe(":8080", nil)
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
package definition
// Note that in this approach both the singleton instance
// and its interface type are declared in the definition
// package. Make sure this package does not contain any
// logic, otherwise it might need to import other packages
// and its neutral nature is compromised.
var (
UserDBInstance UserDB
ConfigDBInstance ConfigDB
)
type UserDB interface {
UserRoleByID(id string) string
}
type ConfigDB interface {
AllPermissions() map[string][]string // maps from role to its permissions
}
1
2
3
package definition
var RolePermissions map[string][]string
1
2
3
4
5
6
7
package database
type SomeUserDB struct{}
func (db *SomeUserDB) UserRoleByID(id string) string {
// implementation
}
1
2
3
4
5
6
7
package database
type SomeConfigDB struct{}
func (db *SomeConfigDB) AllPermissions() map[string][]string {
// implementation
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
package config
import (
"github.com/myproject/definition"
"time"
)
// Since the definition package must not contain any logic,
// managing configuration is implemented in a config package.
func InitPermissions() {
definition.RolePermissions = definition.ConfigDBInstance.AllPermissions()
go func() {
for {
time.Sleep(time.Hour)
definition.RolePermissions = definition.ConfigDBInstance.AllPermissions()
}
}()
}
/handler/user_permissions_by_id.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
package handler
import (
"fmt"
"github.com/myproject/definition"
"net/http"
"strings"
)
func UserPermissionsByID(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := definition.UserDBInstance.UserRoleByID(id)
permissions := definition.RolePermissions[role]
fmt.Fprint(w, strings.Join(permissions, ", "))
}
Approach III: Independent Packages
In this approach we also organize our project in packages. Here, each package must declare all of its dependencies locally via interfaces and variables. This makes it completely unaware of other packages. In this approach, the definition package from the previous approach is actually spread between all the other packages; each package declaring its own interface for every service. This may seem as an annoying duplication at first glance, but it isn’t. Each package that uses a service should declare its own interface, specifying only what it requires from it, omitting the rest. Full code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
package main
// Note how the main package is the only one importing
// other local packages.
import (
"github.com/myproject/config"
"github.com/myproject/database"
"github.com/myproject/handler"
"net/http"
)
func main() {
userDB := &database.SomeUserDB{}
configDB := &database.SomeConfigDB{}
permissionStorage := config.NewPermissionStorage(configDB)
h := &handler.UserPermissionsByID{UserDB: userDB, PermissionsStorage: permissionStorage}
http.Handle("/", h)
http.ListenAndServe(":8080", nil)
}
1
2
3
4
5
6
7
package database
type SomeUserDB struct{}
func (db *SomeUserDB) UserRoleByID(id string) string {
// implementation
}
1
2
3
4
5
6
7
package database
type SomeConfigDB struct{}
func (db *SomeConfigDB) AllPermissions() map[string][]string {
// implementation
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
package config
import (
"time"
)
// Here we declare an interface representing our local
// needs from the configuration db, namely,
// the `AllPermissions` method.
type PermissionDB interface {
AllPermissions() map[string][]string // maps from role to its permissions
}
// Then we export a service than will provide the
// permissions from memory, to use it, another package
// will have to declare a local interface.
type PermissionStorage struct {
permissions map[string][]string
}
func NewPermissionStorage(db PermissionDB) *PermissionStorage {
s := &PermissionStorage{}
s.permissions = db.AllPermissions()
go func() {
for {
time.Sleep(time.Hour)
s.permissions = db.AllPermissions()
}
}()
return s
}
func (s *PermissionStorage) RolePermissions(role string) []string {
return s.permissions[role]
}
/handler/user_permissions_by_id.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
package handler
import (
"fmt"
"net/http"
"strings"
)
// Declaring our local needs from the user db instance,
type UserDB interface {
UserRoleByID(id string) string
}
// ... and our local needs from the in memory permission storage.
type PermissionStorage interface {
RolePermissions(role string) []string
}
// Lastly, our handler cannot be purely functional,
// since it requires references to non singleton instances.
type UserPermissionsByID struct {
UserDB UserDB
PermissionsStorage PermissionStorage
}
func (u *UserPermissionsByID) ServeHTTP(w http.ResponseWriter, r *http.Request) {
id := r.URL.Query()["id"][0]
role := u.UserDB.UserRoleByID(id)
permissions := u.PermissionsStorage.RolePermissions(role)
fmt.Fprint(w, strings.Join(permissions, ", "))
}
That’s it! Those are the 3 levels of abstraction, the first one being the most slim, containing global state and tightly coupled logic, providing the fastest implementation and the least code to write and maintain, the second being a moderate hybrid, and the third completely decoupled and reusable but requiring the most overhead for maintenance.
Pros and Cons
Approach I: Single Package
Pros
- Least code, much faster to implement, less to maintain.
- No packages mean no circular dependencies to keep in mind.
- Easy for testing due to the existence of service interfaces. In order to test some piece of logic, you may set the singleton instances to any implementation you choose (concrete or mock) and then fire the test logic.
Cons
- Single package also means no private access, everything is accessible from everywhere, this puts more responsibility on the developer. For example, remember not to instantiate struct directly when constructor function is required in order to perform some init logic.
- Global state (the singleton instances) may create an unmet assumption, for example, uninitialized singleton instance will cause nil pointer panic at runtime.
- Tightly coupled logic means nothing can easily be extracted or reused from this project.
- Having no packages independently managing pieces of logic also means the developer must be very responsible placing every piece of code correctly, otherwise unexpected behavior may arise.
Approach II: Coupled Packages
Pros
- Packaging our project helps us ensure responsibility of logic per package, and can be enforced by the compiler. Additionally, we can use private access, and have control over what we choose to expose.
- The use of definition package allows for singleton instances while avoiding circular dependencies. This means we can write less code, avoid managing reference passing of instances, and not wasting any time on potential compile issues.
- This approach is also ready for testing due to the existence of service interfaces. With this approach each package may be tested internally.
Cons
- Organizing project in packages has some overhead, the initial implementation will probably take longer than the single package approach.
- The use of global state (singleton instances) in this approach may cause issues as well.
- The project is separated into packages, which makes it much easier to extract and reuse logic. However, the packages are not completely independent since they all interact with the definition package. In this approach extraction of code and reusability are not completely automatic.
Approach III: Independent Packages
Pros
- Packaging helps us ensure responsibility of logic in one package, and have access control.
- No potential circular dependencies since packages are completely independent.
- All packages are completely extractable and reusable. Whenever a package is needed in another project, it can simply be moved to a shared location and used without having to change a thing.
- No global state means no unexpected behavior.
- This approach is the best one for testing. Each package may be completely tested without depending on other packages due to the local interfaces.
Cons
- This approach is a bit slower to implement than the other two.
- A lot more to maintain. Reference passing means we have a lot of places we need to update when we need to write breaking changes. Also, having multiple interfaces representing the same service means we have to update all of them every time we introduce a change to that service.
Conclusions and Use Cases
Given the lack of community guidelines Go code comes in many shapes and forms, each has interesting merits. However, mixing different design patterns may cause problems. To organize this, I’ve introduced three different approaches to write and structure Go code.
So when should each approach be used? I propose the following:
Approach I: The single package approach will probably be the go-to approach when working in small, well-experienced teams on small projects wanting to achieve fast results. This approach is faster and easier to kick start, although it requires much caution and coordination when maintaining due to lack of enforcement capabilities.
Approach II: The coupled packages approach is kind of a hybrid fusion of the other two, it has the advantages of being relatively fast and easy to maintain, while having most of the enforcement capabilities. It may be used for bigger projects by bigger teams, but still lacks reusability and has some overhead maintaining.
Approach III: The independent packages approach may suit projects of a more complex nature, bigger projects, projects that are probably more long term, worked on by bigger teams, or projects that contain pieces of logic that will probably be reused later on. This approach has a longer implementation time, and takes more time to maintain.
At HUMAN, we use a combination of the latter two. We implement common libraries using the independent packages approach and write our services using the coupled packages approach. I’d like to invite you to share with us your take on Go code structuring. Do you have another approach to offer? Do you have any improvements for the approaches proposed here? Let’s hear your thoughts.