TL;DR: This is a story about the internal journey we had in HUMAN Security to find the best project structure for Go, the decisions we’ve made, and the conclusions we’ve drawn. We’ve created an open-source template repository for the final structure, and a branch containing an example project alongside. To use this template, fork the repository or use it as a template. To learn more about it, keep reading.
Structuring Architecture
By now, we’ve defined our structuring approach: we want packages to be independent of one another and communicate via dependency injection. We’ve also defined our goals:
- Structural coherence
- Separation of business logic and infrastructure
- Reusability
- Dependency declaration
Now we work to find the matching architecture for our projects. Each of the architectures and structures presented below is a complex subject worth exploring in depth, but in the interest of brevity, I’ll try to provide only a quick overview and links for further reading. If you’re interested in any of them, I suggest learning them in dedicated posts and articles.
Clean Architecture
Clean architecture divides software into layers in order to achieve separation of concerns. As suggested by the following diagram, clean architecture divides the code into four layers:
- External interfaces (communicate with the outside world)
- Interface adapters (external world abstractions to achieve business logic - infrastructure separation)
- Business logic
- Business entities
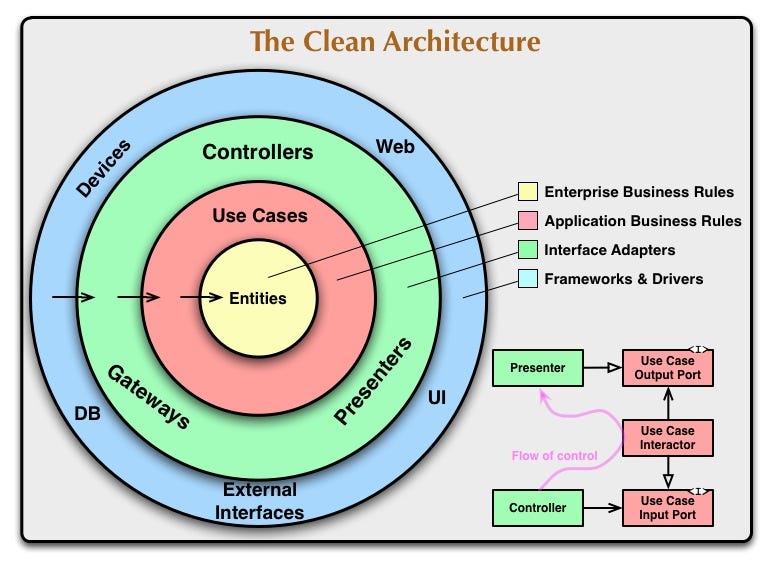
Credit: https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
Some quick reading about Clean architecture here.
We considered Clean architecture to be a very interesting approach, as it enables us to meet all the goals we’ve set.
Hexagonal Architecture
Also known as the “ports and adapters” pattern, hexagonal architecture divides software into two layers:
- External interfaces, which is further divided into two:
- Ports (inbound infrastructure, like an HTTP server, for example)
- Adapters (outbound infrastructure, like an HTTP client, for example)
- Business logic
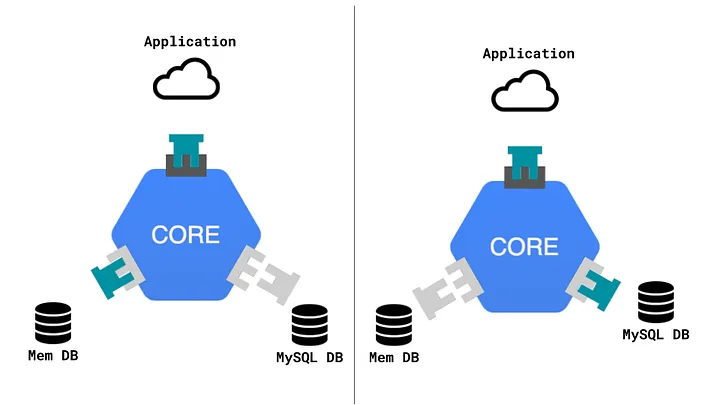
Credit: https://medium.com/@matiasvarela/hexagonal-architecture-in-go-cfd4e436faa3
Some quick reading about hexagonal architecture can be found here.
Hexagonal architecture also allows us to meet all the goals we’ve set. However, it is far less opinionated than Clean architecture. It means we can be more dynamic with future decisions, and it allows us to solve future problems with less friction.
Domain-Driven Design
This approach is more complex and nuanced, and I like to say it contains both a philosophy for designing and approaching software and a practical structure to follow when implementing it.
As a brutally short overview of the philosophy behind it, I’ll mention that according to DDD, each software belongs to a specific business domain. This business domain is then modeled into software while continuously collaborating with domain experts using agreed-upon terminology.
As to the practical structure, domain-driven design divides software into the following components:
- Entity - a struct that has an Identifier and that can change state.
- Value Object - an immutable object that has attributes, but no distinct identity.
- Aggregate - a cluster of entities and value objects with defined boundaries around the group.
- Service - an operation or form of business logic that doesn’t naturally fit within the realm of objects.
- Repositories - a service that provides access to all entities and value objects that are within a particular aggregate collection.
- Factories - encapsulate the logic of creating complex objects and aggregates.
As I mentioned, DDD is a complex subject. Further reading can be done in the official book, or here, here, here, and here.
Domain-driven design offers an insightful philosophy for approaching software. We’ve adopted everything it offers as it pertains to managing projects and terminology guidelines. However, its structural guidelines were too strict and far too opinionated to solve all our needs while addressing different KPIs, like performance, development velocity, and more. We want to avoid future discussions for new components that don’t naturally fit one of the above categories. We’ve decided to go with hexagonal since it leaves those kinds of decisions for the designer of each project or component.
Modular Structure
As presented by Kat Zień in a GopherCon 2018 talk, modular structure divides software by business use cases rather than technical functions. Note how in this structure, each business logic unit, contains both business logic and the infrastructure needed to enable it.
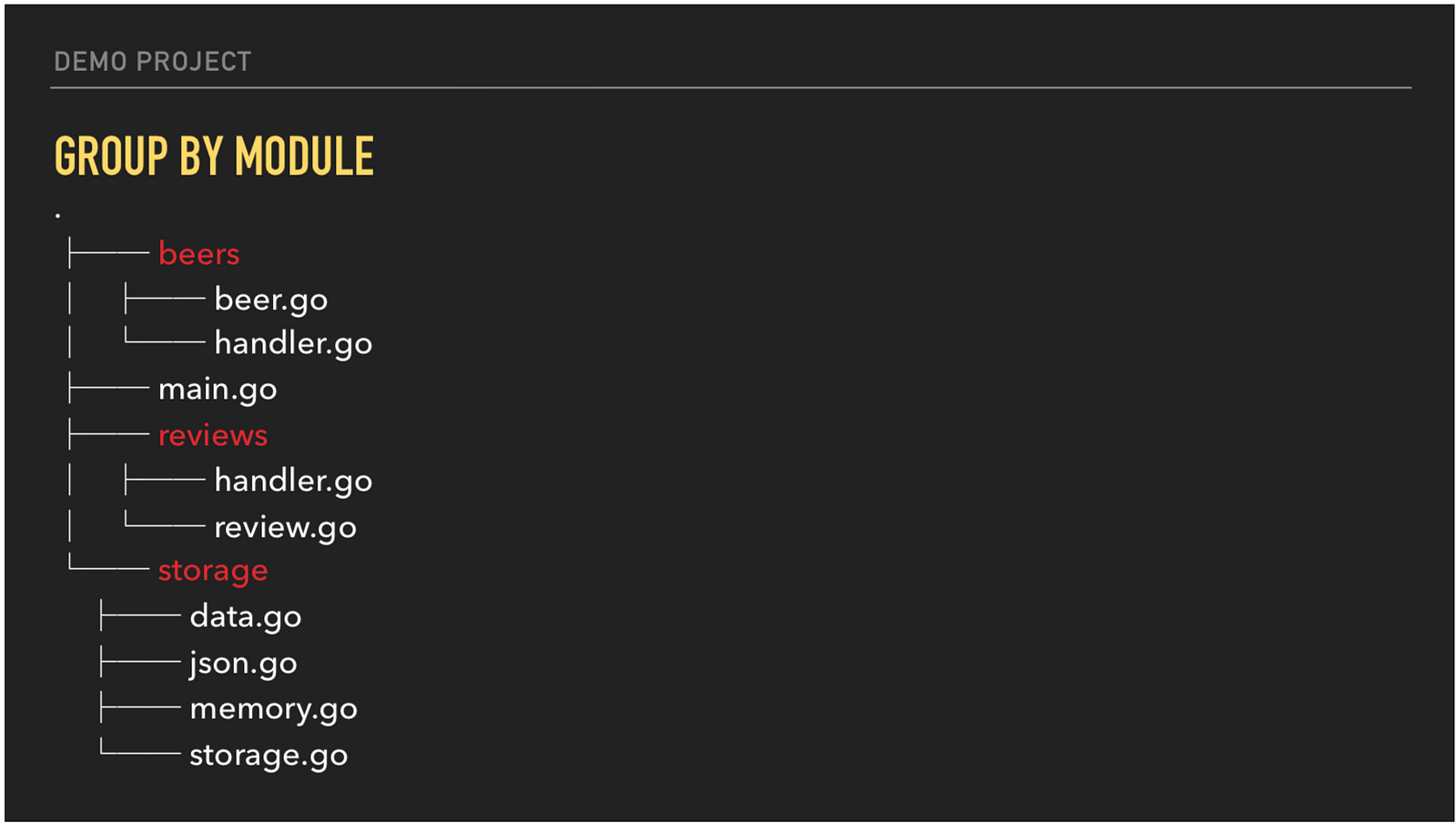
Further reading here.
We agreed modular structure is a very interesting approach. It might, however, interfere with our efforts to keep business logic and infrastructure separated. If we implement infrastructure separately in each business domain, it will be much harder to manage and keep the advantages of separation presented earlier.
In the end, we decided to adopt hexagonal architecture as it is the least opinionated option, and it elegantly meets all our requirements. Furthermore, we’ve decided to adopt some philosophy principles from the domain-driven realm, and lastly, use a modular structure approach within our business logic layer.
Package Structure
Great! Now we have our structuring approach - independent packages - and our new structuring architecture - hexagonal architecture - so what remains is to define a concrete package structure. Initially, we considered applying hexagonal architecture as a directory structure directly. That means a package for business logic (which we name core), a package for adapters, and one for ports.
1
2
3
4
5
6
7
8
9
10
.\
|-- adapter\
| |-- http_slack_client.go\
| `-- mysql_user_db.go\
|-- core\
| |-- notification\
| | `-- notification_service.go\
`-- port\
|-- http_server.go\
`-- kafka_consumer.go
The first downside we’ve experienced here was the lack of separation between infrastructure domains. We have one package for all adapters and one package for all ports. This means components of different domains or technologies live within the same package. In the example above, HTTP adapters and MySQL adapters share a package together. But there shouldn’t be any shared code between the two. Why? Let’s think of an example:
Suppose we have two different ways of communicating with a remote server: via HTTP or via gRPC. Our codebase contains both implementations as different clients in the adapter package. Now suppose we have some shared code between the two. For example, calculating the timeout of a request. Note that this piece of logic is infrastructure agnostic. Meaning, it doesn’t really matter if we use HTTP or gRPC. Instead, it’s a constant logic we execute regardless of infrastructure. This is the exact definition of business logic. This piece of code belongs in the core layer.
Our rule of thumb: there shouldn’t be any shared code between different domains of infrastructure packages. We decided to create a dedicated package for each domain. Another benefit we gain from this structural change: now the HTTP code and the gRPC have separate and cleaner namespaces. The updated structure looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
.\
|-- adapter\
| |-- http\
| | `-- http_slack_client.go\
| `-- mysql\
| `-- mysql_user_db.go\
|-- core\
| |-- notification\
| | `-- notification_service.go\
`-- port\
|-- http\
| `-- http_server.go\
`-- kafka\
`-- kafka_consumer.go
There are two further downsides to this structure:
First, it does make sense for ports and adapters of the same domain to share some code. For example, it does make sense for an HTTP server and HTTP client to have the same code for handling HTTP status codes. When ports and adapters of the same domain are not defined in the same package, we lose this ability.
Second, as you can see, we potentially have two different packages for each infrastructure domain. In the example above we have two http packages. This creates ambiguity in the entire project. Also, if one file requires both of them, we must create import aliases to avoid a naming collision. Ugh.
We fix those by merging the adapter and port packages into a unified infra package:
1
2
3
4
5
6
7
8
9
10
11
12
.\
|-- core\
| |-- notification\
| | `-- notification_service.go\
`-- infra\
|-- http\
| |-- http_server.go\
| `-- http_slack_client.go\
|-- kafka\
| `-- kafka_consumer.go\
`-- mysql\
`-- mysql_user_db.go
This is better. Note that the http package in this example contains both ports and adapters.
What about ambiguity between internal packages and external ones? What if we want to import both our internal infra/http package and the native http package? We still have naming collisions, right? Nope. Any HTTP-specific code should be placed inside our internal infra/http package. Inside, it should import the native http package without any ambiguity. Anything outside of that package must not directly interact with the native http package, but import and use the features of our infra/http instead. In fact, you can use it as a static check for your code.
Directory Structure
Lastly, we need to settle on a directory structure convention. Out of everything we found out there for Go projects, we’ve adopted the following:
cmd- the cmd layout pattern is useful when you have more than one executable or entry point. Each executable has its own cmd dir (for examplecmd/server/main.goandcmd/cli/main.gofor a project that has both a server and a CLI application).internal- since Go 1.4, Go’s compiler supports internal packages. Any package placed inside an internal package is only importable from within the same directory root. In other words, internal packages allow you to store packages you wish to use for the current project but don’t wish other projects to use.pkg- is a popular package name to store packages that you do wish to share with other projects. In other words, if an internal package is private, a pkg package is public. As opposed to internal, the pkg directory has no special support within the Go compiler. This is simply a popular convention.
Connecting All The Dots
To summarize the resulting structure, we’ve created an example repository implementing our structural rules and guidelines. The example branch contains a simple TODO application to manage tasks. The main branch contains an empty skeleton for creating new repositories. To use the structure, fork the repo, or use it as a GitHub template. Have any questions? Disagreements? We would love to hear from you! Submit a GitHub issue, or comment on social media. ❤️